Paraphrase identification. A Kaggle competition
Finding repeated questions in discussion forums is fairly common and that can be a problem. Multiple similar questions lead seekers to find the best answer in different posts, and writers to answer the same question multiple times. So, to improve the user experience it is necessary to avoid these repeated questions through paraphrase identification.
Paraphrase identification is a hard problem which involves Natural Language Processing (NLP) and Machine Learning. For this reason, Quora launched the Quora Question Pairs Competition in Kaggle.
In this competition, Quora provides a training dataset with pairs of questions (400K) labeled to 1 if the two questions have the same meaning or 0 if not, and a test dataset with pairs of questions (2.3M) unlabeled. Since these questions have been tagged by humans, their labels are inherently subjective, so they are not 100% accurate. The objective is to predict if both questions for each sample share the same meaning.

Architecture
To solve this problem I propose an architecture based on Recurrent Neural Networks. This kind of networks has proven its performance on different NLP tasks like sentiment analysis or text translation.
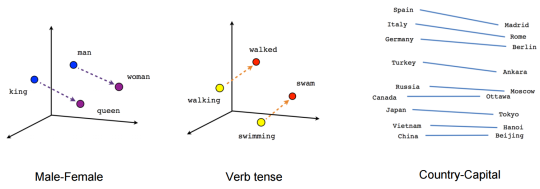
Since the input of the network must be numeric, questions must be transformed to arrays of Word Embeddings. A Word Embedding is a vector which represents a word in a multidimensional space. Once the embeddings are trained, the resulting word vectors have quite interesting spatial characteristics which are useful to the model to train.
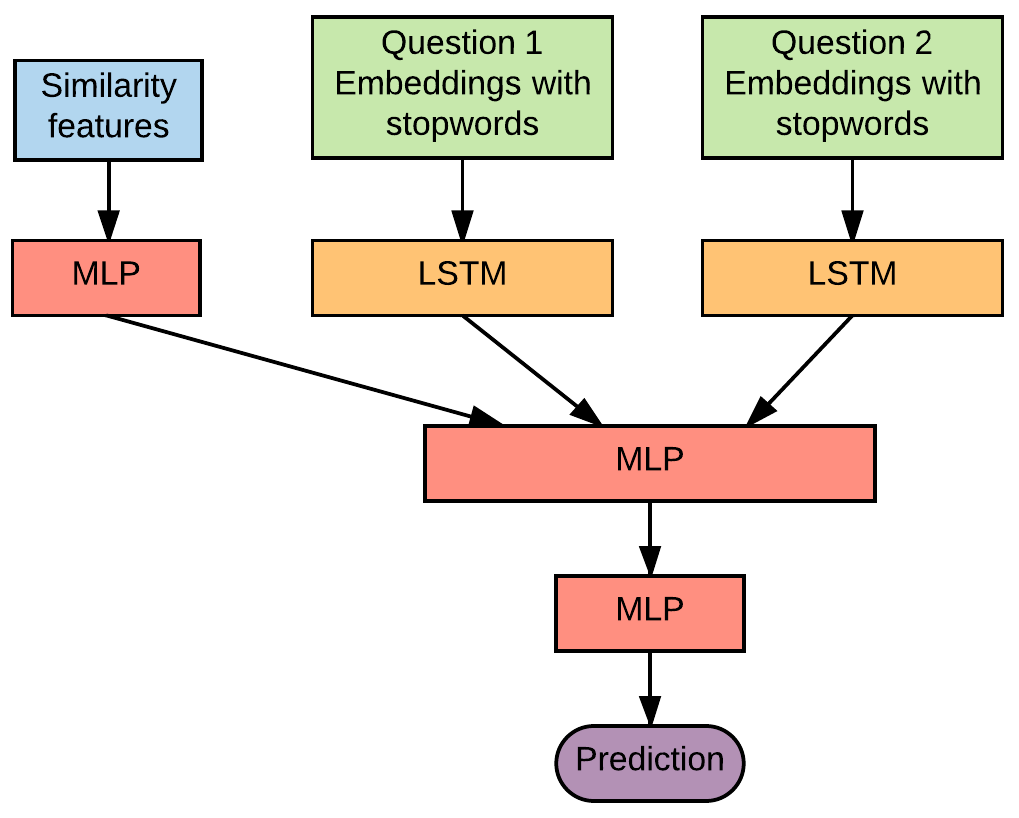
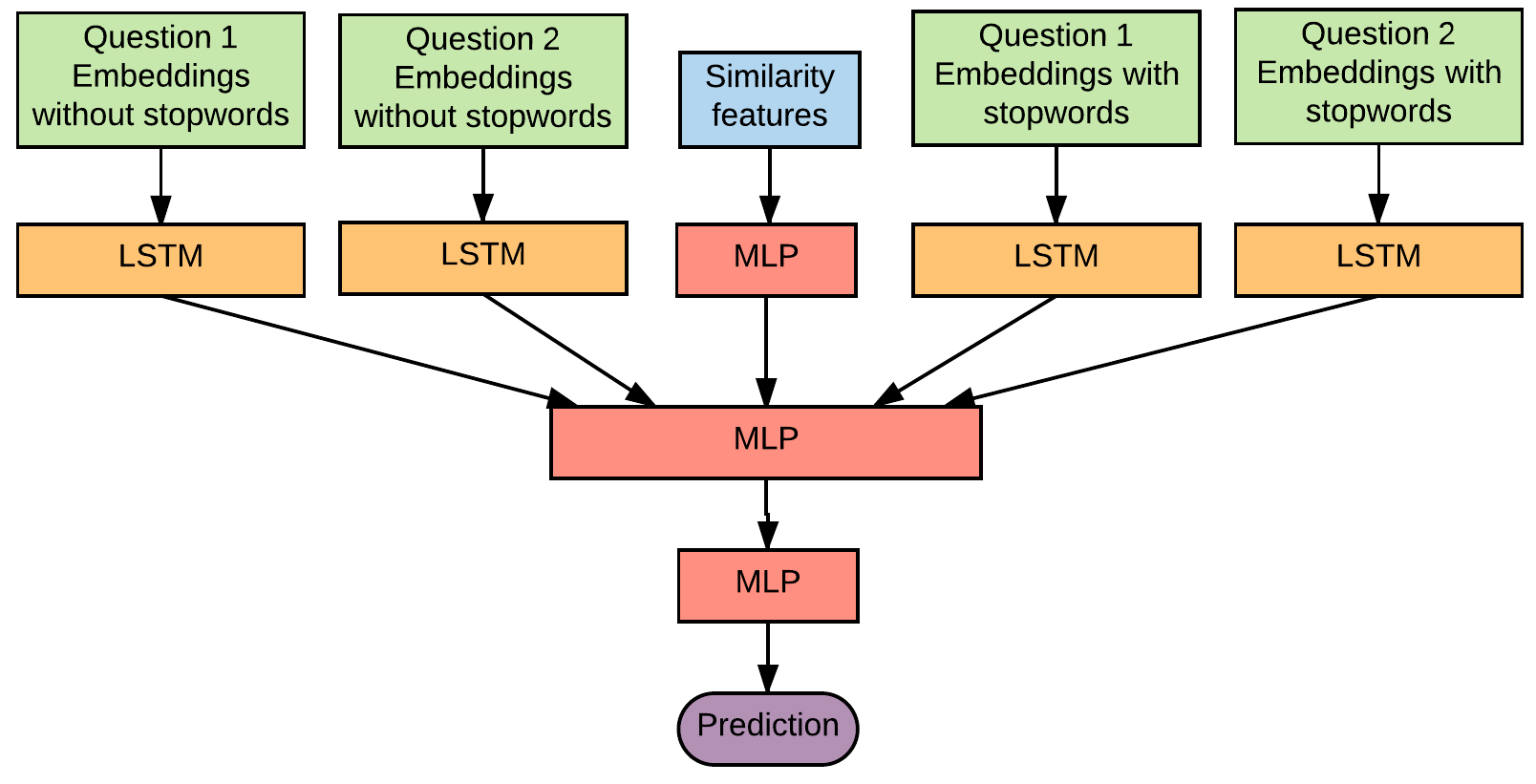
Following this approach, the network’s input is a pair of word embeddings arrays. Each of these arrays is processed by a LSTM layer whose function is to learn its temporal patterns. In order to reduce the training time and the number of parameters, and since both input questions share the same format, the weights which process both questions are the same. The output of this pair of LSTMs is concatenated and taken as the input of the next Multilayer Perceptron (MLP), and finally, the last layer is a single neuron with the sigmoid activation function which returns the probability that both questions share the same meaning.
Additionally, a set of features have been calculated and taken as the third input of the Neural Network. This new input is concatenated to one of the MLP layer. This is the final architecture:
Feature Engineering
Feature Engineering is one of the most important part in a Data Science project. For this project there are two kinds of features, those related with question representations and those related with similarities.
As I mentioned above, each word is represented as a vector and each question as a sequence of vectors. However, learning these Word Embeddings requires a big amount of data to get consistent results. To avoid this step I have used pretrained Word Embeddings from GloVe. Specifically I have used those trained with data from a Common Crawl with 840B tokens and 2.2M words represented as a 300-dimensional vector.
Before using these embeddings, each question has to be preprocessed. NLP cleaning includes steps like setting all characters to lower case, removing odd characters, removing stopwords, stemming (not in this project), and convert each sentence to an array of indexes, where each index points to a word representation in an Embedding Layer and each row of its weights represents a word vector.
Besides Word Embeddings, some features related to the question similarities has been calculated for each pair of questions. Some of these features are cosine similarities, Levenshtein distance, Jaro distance and ratio (more info here). These features have been calculated with and without stopwords in the questions.
Model Stacking
This Neural Network has been trained several times with different modifications in its architecture and inputs. For this set of trainings, questions have been taken as inputs after removing (or not) stopwords, the architecture has been modified adding more layers (including Dropout and Batch Normalization) or increasing their size, and distance features are taken as an input to concatenate before (or not) been processed by a MLP layer. All of these models have achieved an accuracy between 88% and 91% with the full labeled dataset.
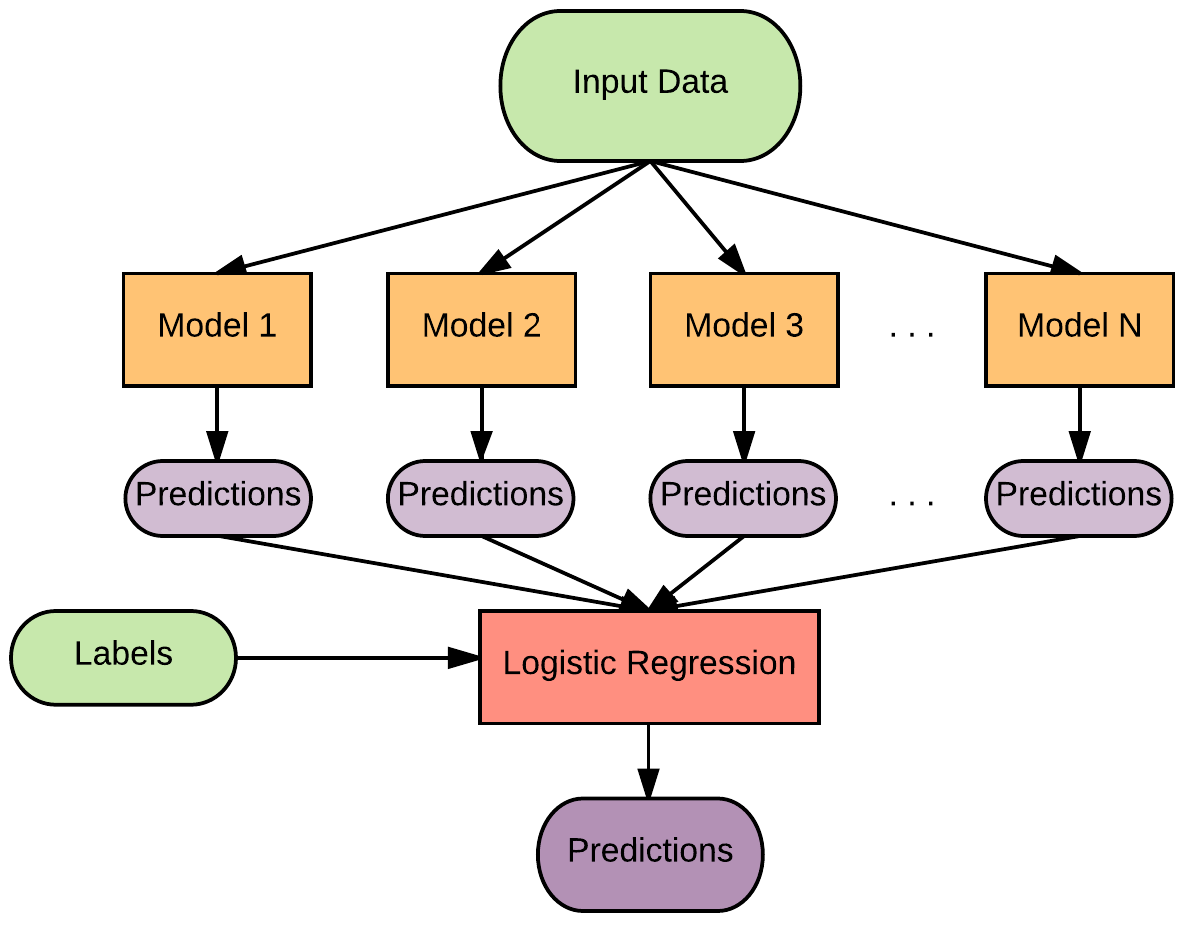
To improve this metric, all of these models have been combined to make a Stacked Model. This means that one model has been trained only with the predictions of the previous models in order to increase the global accuracy. To do this, it isn’t necessary to use a complex algorithm, a Logistic Regression is enough.
An additional stacked model has been trained with the main Neural Network architecture. Its inputs are the pretrained Word Embeddings, the predictions obtained with the previous trained models for each pair of questions and its similarity features.
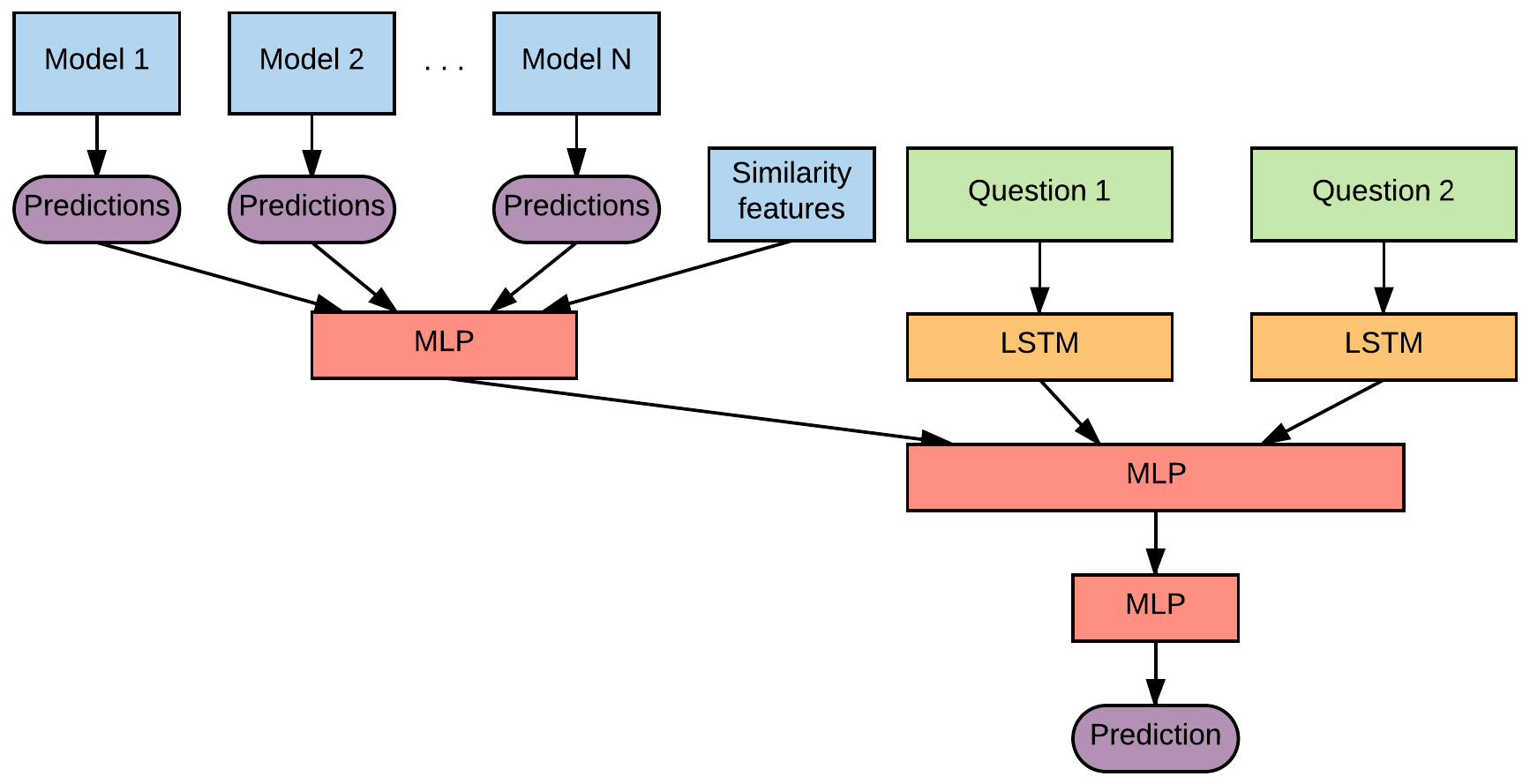
Both stacked models have increased the final accuracy to ~94%.
What didn’t work
At the beginning of the competition, I tried to do feature engineering with a Correspondence Analysis. Using this unsupervised learning technique, from a contingency matrix with the count of each possible word for each question, I would be able to represent each word or question in a multidimensional space where similar words or questions are close to each other. In this way, these vectors allow similarity and distance calculation. This method would also allow clustering or calculating word or question representations, to feed an upper model.
However, I realized (too late) that this technique wasn’t scalable at all. The contingency matrix was so big that it didn’t fit in memory. So, I had to discard this method.
A similar approach I tried was to use PCA instead of CA over the contingency matrix. Although both methods are different, the expected result is similar, questions represented as multidimensional vectors. To run PCA, I had to run this algorithm by batches of the contingency matrix. It fits in memory, but it was extremely time expensive (remember that the full dataset has 2.7M questions). So, another technique discarded.
As the dataset was so big, I also tried to learn the word embeddings at the same time the Neural Network was trained. Didn’t work. Word Embeddings are usually trained using word2vec. I didn’t try it because there are lot of embeddings trained with this technique available like GloVe.
Another architecture I tried to use was a Neural Network with LSTM layers like the described before, but with 4 questions as inputs instead of two. Two questions with stopwords and two more without stopwords. I tried, but my GPU memory isn’t big enough to fit that model.
Another important thing I would have changed is to work with all data from the beginning. The train dataset is quite huge, and as I work with a laptop, a complete training to tune hyperparameters or feature engineering takes too much time. So, a better solution would have been to work with a subset of the dataset and use the full data to train the final models.
Work to do
In projects like this, the principal resource is time. I would have liked to have more time to spend reading related papers, studying the stat-of-the-art, reading Kaggle kernels, etc.
Besides that, I would also like to have worked more with feature engineering. This is some work that could have been done:
- Tf-idf: this technique provides knowledge about how important is a word according to the number of times it appears in a question and in all dataset.
- Autoencoders: an autoencoder is a Neural Network whose function is, through unsupervised learning, learn a new representation (code) for its inputs. Its architecture is made of an encoder, which creates the code from its input, and a decoder, which reconstruct the input from the code. So, this code can be a new representation for our questions that feed the models. To do that, the autoencoder must be made of Convolutional or LSTM layers.
- Get features from words which are out of the embeddings dataset. Ex. see if excluded words are in both questions, calculate feature similarities from the excluded words, etc.
- Get features from n-grams instead of words. That can help with misspelled words.
More architectures I would have liked to try:
- Convolutional Neural Networks: use convolutional layers instead of LSTM. Probably the final results had not been as good, but the training would have been much faster.
- Mix of convolutional and recurrent layers: use a convolutional layer before each LSTM to preprocess the embedding.
- More algorithms: feed algorithms like XGBoost or Random Forests with the embeddings and features.
More solutions
If you finished reading this post and you are still interested in Paraphrase Identification or NLP, I recommend you to read other solutions for this competition. Enjoy!
Code
Full code is available here.